当我们开始使用神经网络的时候,我们会经常用到激活函数,这是因为激活函数是任何神经网络结构中不可或缺的一部分。激活函数的目的是调整权重和偏差。在TensorFlow中,激活函数是作用在张量上非线性的操作符。它们很像前面一节的数学运算符, 应用比较广泛,但是它们主要的贡献是引入计算图中非线性的计算。同样,我们需要运行一下下面的命令来创建一个 graph session :
>>> import tensorflow.compat.v1 as tf
>>> import matplotlib.pyplot as plt
>>> import numpy as np
>>> from tensorflow.python.framework import ops
>>> ops.reset_default_graph()
# 下面一行命令必须放在上面命令运行完之后,不可调换,否则容易出现empty graph
>>> tf.disable_eager_execution()
>>> sess = tf.Session()
激活函数都是存在于TensorFlow中神经网络(Neural Network)库中 tensorflow.nn 。除了使用内置激活函数,我们也可以使用TensorFlow运算来设计自己的激活函数。我们可以导入预先设定的函数( import tf.nn as nn ) 或更精确一点采用 ( tf.nn )。
线性整流函数(Rectifed Linear Unit)¶
>>> x_vals = np.linspace(start=-10,stop=10,num=100)
>>> print(sess.run(tf.nn.relu([-3.,3.,10.])))
[ 0. 3. 10.]
>>> y_relu = sess.run(tf.nn.relu(x_vals))
>>> plt.plot(x_vals, y_relu, 'b:', label='ReLU', linewidth=2)
... plt.ylim([-5,11])
... plt.legend(loc='upper left')
... plt.show()

如上图所示,ReLU是最普遍和最基本的方法想神经网络结构中引入非线性。这个函数从本质上来讲,仅仅就是 max(0,x) , 它是连续的但是不光滑。
ReLUn函数¶
有时候,我们想增加前面的ReLU激活函数的线性部分。我们可以将 max(0,x) 函数放在 min() 函数里面。TensorFlow有一个应用函数叫做 ReLU6 函数。这个函数被定义为 min(max(0,x),6)。 它是非光滑S型函数(hard-sigmoid function),计算非常快,而且并不会受到 vanishing(无限接近于零)或者 exploding 数值. 这些都会在第八章卷积神经网络和第九章递归神经网络中进行详细地讨论。
>>> x_vals = np.linspace(start=-10,stop=10,num=100)
>>> y_relu6 = sess.run(tf.nn.relu6(x_vals))
... plt.plot(x_vals, y_relu6, 'g-.', label='ReLU6', linewidth=2)
... plt.ylim([-5,11])
... plt.legend(loc='upper left')
... plt.show()

S型函数(Sigmoid)¶
S型函数是最普遍基本光滑的激活函数。它有时候也叫做逻辑函数,有着 \(\frac{1}{1+e^{x}}\) 的形式。Sigmoid并不经常用,是因为在训练过程中,它有抵消反向传播的趋势。
>>> x_vals = np.linspace(start=-10,stop=10,num=100)
>>> print(sess.run(tf.nn.sigmoid([-1.,0.,1.])))
>>> plt.plot(x_vals, y_sigmoid, 'y-..', label='Sigmoid', linewidth=2)
... plt.ylim([0,1])
... plt.legend(loc='upper left')
... plt.show()

我们需要知道是有些激活函数不是zero-centered, 例如sigmoid函数。 这就需要我们在大多数计算图算法中,先对数据进行零平均,然后再使用它。
\(\tanh\) 函数¶
另外一个平滑的激活函数就是 \(\tanh\) (hyper tangent). \(\tanh\) 函数很像 sigmoid 函数,与之不同的是,前者它的值域在 \([-1,1]\) 之间。这个函数的形式是 \(\frac{\sinh}{\cosh}\), 它的另一种形式是 \(\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}}\) 。
>>> x_vals = np.linspace(start=-10,stop=10,num=100)
>>> print(sess.run(tf.nn.tanh([-1.,0.,1.])))
>>> y_tanh = sess.run(tf.nn.tanh(x_vals))
>>> plt.plot(x_vals, y_tanh, 'b:', label='Tanh', linewidth=2)
... plt.ylim([-2,2])
... plt.legend(loc='upper left')
... plt.show()

softsign 函数¶
softsign 函数也会被经常用着激活函数,它拥有着 \(\frac{x}{\left| x \right|+1}\) 数学形式。 softsign 是 soft 函数的近似。
>>> x_vals = np.linspace(start=-10,stop=10,num=100)
>>> print(sess.run(tf.nn.softsign([-1.,0.,1.])))
[-0.5 0. 0.5]
>>> y_softsign = sess.run(tf.nn.softsign(x_vals))
>>> plt.plot(x_vals, y_softsign, 'g-.', label='Softsign', linewidth=2)
... plt.ylim([-1,1])
... plt.legend(loc='upper left')
... plt.show()

softplus 函数¶
softplus 函数是 ReLU 函数的光滑版本,它有着 \(\log(e^{x}+1)\) 的形式。
>>> x_vals = np.linspace(start=-10,stop=15,num=100)
>>> print(sess.run(tf.nn.softplus([-1.,0.,1.])))
[0.31326166 0.6931472 1.3132616 ]
>>> y_softplus = sess.run(tf.nn.softplus(x_vals))
>>> plt.plot(x_vals, y_softplus, 'r--', label='Softplus', linewidth=2)
... plt.ylim([-2,15])
... plt.legend(loc='upper left')
... plt.show()

Exponential Linear Unit(ELU)函数¶
指数线性单元(ELU)函数很像 softplus 函数,但是底渐近线是-1而不是0, 它有着 \(\begin{cases}e^{x}+1, x<0 \\x, x\ge 0 \end{cases}\) 的数学形式。
>>> x_vals = np.linspace(start=-10,stop=10,num=100)
>>> print(sess.run(tf.nn.elu([-1., 0., 1.])))
[-0.63212055 0. 1. ]
>>> y_elu = sess.run(tf.nn.elu(x_vals))
>>> plt.plot(x_vals, y_elu, 'k-', label='ExpLU', linewidth=0.5)
... plt.ylim([-2,10])
... plt.legend(loc='upper left')
... plt.show()

总结¶
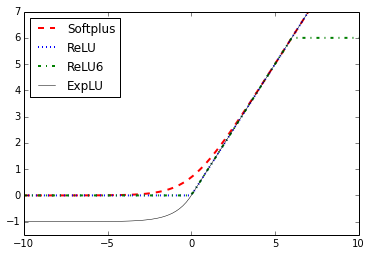
以上函数可以放在一起进行比较。
>>> plt.plot(x_vals, y_softplus, 'r--', label='Softplus', linewidth=2)
... plt.plot(x_vals, y_relu, 'b:', label='ReLU', linewidth=2)
... plt.plot(x_vals, y_relu6, 'g-.', label='ReLU6', linewidth=2)
... plt.plot(x_vals, y_elu, 'k-', label='ExpLU', linewidth=0.5)
... plt.ylim([-1.5,7])
... plt.legend(loc='upper left')
... plt.show()
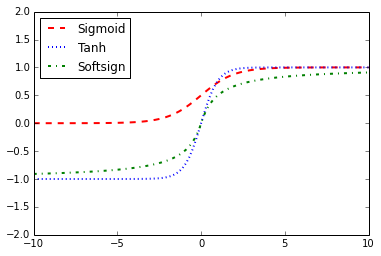
>>> plt.plot(x_vals, y_sigmoid, 'r--', label='Sigmoid', linewidth=2)
... plt.plot(x_vals, y_tanh, 'b:', label='Tanh', linewidth=2)
... plt.plot(x_vals, y_softsign, 'g-.', label='Softsign', linewidth=2)
... plt.ylim([-2,2])
... plt.legend(loc='upper left')
... plt.show()
机器学习是什么鬼?¶
神经网络结构有很多种。不过,无论你选择什么结构,在训练过程中涉及的数学运算都不会改变(执行什么样的计算并且按照什么顺序)。我们在训练过程中更新的是内部变量(权重和偏差)。 例如,在摄氏度到华氏度转换问题中,模型首先将输入乘以某个数字(权重),并与另一个数字(偏差)相加。训练模型是指为这些变量寻找合适的值,而不是从乘法和减法变成其他运算。
这是一个很有趣的点。如果你解决了视频中的摄氏度到华氏度转换问题,可能是因为你之前就知道如何将摄氏度转换为华氏度。例如,你可能知道 0 摄氏度等于 32 华氏度。但是机器学习从来不知道这些知识。它们在不知道任何其他知识的情况下学习解决这些类型的问题。
本节学习模块¶
注意
Rectified Linear Unit(ReLU)函数介绍
Computes rectified linear: max(features, 0).
See: https://en.wikipedia.org/wiki/Rectifier_(neural_networks) Example usage: >>> tf.nn.relu([-2., 0., 3.]).numpy() array([0., 0., 3.], dtype=float32)
| param features: | A Tensor. Must be one of the following types: float32, float64, int32, uint8, int16, int8, int64, bfloat16, uint16, half, uint32, uint64, qint8. |
|---|---|
| param name: | A name for the operation (optional). |
| returns: | A Tensor. Has the same type as features. |
注意
Rectified Linear Unit6(ReLU6)函数介绍
Computes Rectified Linear 6: min(max(features, 0), 6).
In comparison with tf.nn.relu, relu6 activation functions have shown to empirically perform better under low-precision conditions (e.g. fixed point inference) by encouraging the model to learn sparse features earlier. Source: [Convolutional Deep Belief Networks on CIFAR-10: Krizhevsky et al., 2010](http://www.cs.utoronto.ca/~kriz/conv-cifar10-aug2010.pdf).
For example:
>>> x = tf.constant([-3.0, -1.0, 0.0, 6.0, 10.0], dtype=tf.float32)
>>> y = tf.nn.relu6(x)
>>> y.numpy()
array([0., 0., 0., 6., 6.], dtype=float32)
| param features: | A Tensor with type float, double, int32, int64, uint8, int16, or int8. |
|---|---|
| param name: | A name for the operation (optional). |
| returns: | A Tensor with the same type as features. |
References
- Convolutional Deep Belief Networks on CIFAR-10:
- Krizhevsky et al., 2010 ([pdf](http://www.cs.utoronto.ca/~kriz/conv-cifar10-aug2010.pdf))
注意
Sigmoid函数介绍
Computes sigmoid of x element-wise.
Formula for calculating $mathrm{sigmoid}(x) = y = 1 / (1 + exp(-x))$.
For $x in (-infty, infty)$, $mathrm{sigmoid}(x) in (0, 1)$.
Example Usage:
If a positive number is large, then its sigmoid will approach to 1 since the formula will be y = <large_num> / (1 + <large_num>)
>>> x = tf.constant([0.0, 1.0, 50.0, 100.0])
>>> tf.math.sigmoid(x)
<tf.Tensor: shape=(4,), dtype=float32,
numpy=array([0.5, 0.7310586, 1.0, 1.0], dtype=float32)>
If a negative number is large, its sigmoid will approach to 0 since the formula will be y = 1 / (1 + <large_num>)
>>> x = tf.constant([-100.0, -50.0, -1.0, 0.0])
>>> tf.math.sigmoid(x)
<tf.Tensor: shape=(4,), dtype=float32, numpy=
array([0.0000000e+00, 1.9287499e-22, 2.6894143e-01, 0.5],
dtype=float32)>
| param x: | A Tensor with type float16, float32, float64, complex64, or complex128. |
|---|---|
| param name: | A name for the operation (optional). |
| returns: | A Tensor with the same type as x. |
Usage Example:
>>> x = tf.constant([-128.0, 0.0, 128.0], dtype=tf.float32)
>>> tf.sigmoid(x)
<tf.Tensor: shape=(3,), dtype=float32,
numpy=array([0. , 0.5, 1. ], dtype=float32)>
@compatibility(scipy) Equivalent to scipy.special.expit @end_compatibility
注意
tanh函数介绍
Computes hyperbolic tangent of x element-wise.
Given an input tensor, this function computes hyperbolic tangent of every element in the tensor. Input range is [-inf, inf] and output range is [-1,1].
>>> x = tf.constant([-float("inf"), -5, -0.5, 1, 1.2, 2, 3, float("inf")]) >>> tf.math.tanh(x) <tf.Tensor: shape=(8,), dtype=float32, numpy= array([-1.0, -0.99990916, -0.46211717, 0.7615942 , 0.8336547 , 0.9640276 , 0.9950547 , 1.0], dtype=float32)>
| param x: | A Tensor. Must be one of the following types: bfloat16, half, float32, float64, complex64, complex128. |
|---|---|
| param name: | A name for the operation (optional). |
| returns: | A Tensor. Has the same type as x. If x is a SparseTensor, returns SparseTensor(x.indices, tf.math.tanh(x.values, …), x.dense_shape) |
注意
softsign函数介绍
Computes softsign: features / (abs(features) + 1).
| param features: | A Tensor. Must be one of the following types: half, bfloat16, float32, float64. |
|---|---|
| param name: | A name for the operation (optional). |
| returns: | A Tensor. Has the same type as features. |
注意
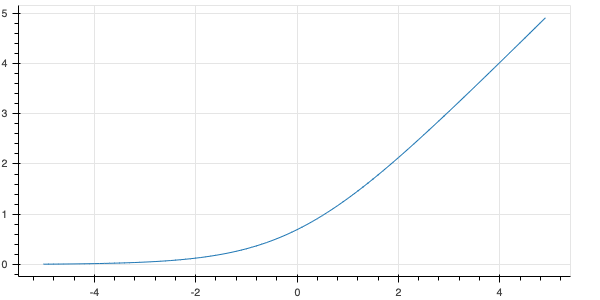
softplus函数介绍
Computes elementwise softplus: softplus(x) = log(exp(x) + 1).
softplus is a smooth approximation of relu. Like relu, softplus always takes on positive values.
<img style=”width:100%” src=”https://www.tensorflow.org/images/softplus.png”>
{kind=link}
Example:
>>> import tensorflow as tf
>>> tf.math.softplus(tf.range(0, 2, dtype=tf.float32)).numpy()
array([0.6931472, 1.3132616], dtype=float32)
| param features: | Tensor |
|---|---|
| param name: | Optional: name to associate with this operation. |
| returns: | Tensor |
注意
Exponential Linear Unit函数介绍
Computes the exponential linear function.
The ELU function is defined as:
- $ e ^ x - 1 $ if $ x < 0 $
- $ x $ if $ x >= 0 $
Examples:
>>> tf.nn.elu(1.0)
<tf.Tensor: shape=(), dtype=float32, numpy=1.0>
>>> tf.nn.elu(0.0)
<tf.Tensor: shape=(), dtype=float32, numpy=0.0>
>>> tf.nn.elu(-1000.0)
<tf.Tensor: shape=(), dtype=float32, numpy=-1.0>
See [Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs) ](http://arxiv.org/abs/1511.07289)
| param features: | A Tensor. Must be one of the following types: half, bfloat16, float32, float64. |
|---|---|
| param name: | A name for the operation (optional). |
| returns: | A Tensor. Has the same type as features. |